本文参考:https://learnopengl.com/。
长文预警 (〃'▽'〃) (。・ω・。) φ(>ω<*)
Advance
Depth testing
深度缓冲会以 16、24 或 32 位 float 的形式储存每个片段中的深度值,通常和颜色缓冲有着一样的宽度和高度。
大部分的系统中,深度缓冲的精度都是 24 位的。
当深度测试(Depth Testing)被启用,OpenGL会将一个片段的深度值与深度缓冲的内容进行对比,执深度测试。如果测试通过,深度缓冲将会更新为新的深度值;如果测试失败,片段会被丢弃。
深度缓冲是在片段着色器运行之后,在屏幕空间中运行的。屏幕空间坐标与 glViewport 定义的视口密切相关,可以使用 gl_FragCoord 从片段着色器中直接访问,x 和 y 分量代表了片段的屏幕空间坐标,(0, 0)位于左下角。
gl_FragCoord 的 z 分量,是片段真正的深度值,也是与深度缓冲内容所对比的那个值。
大部分 GPU 都提供提前深度测试(Early Depth Testing)的硬件特性,允许深度测试在片段着色器之前运行。
只要清楚一个片段永远不会是可见的(在其他物体之后),就能提前丢弃这个片段。
片段着色器开销很大,应该尽可能避免运行。当使用提前深度测试时,片段着色器的限制是不能写入片段的深度值。如果片段着色器对它的深度值进行了写入,就不能提前深度测试,OpenGL 不能提前知道深度值。
深度测试默认禁用,用 GL_DEPTH_TEST 选项来启用:
glEnable(GL_DEPTH_TEST);当启用深度测试后,如果一个片段通过了深度测试,OpenGL 会在深度缓冲中储存该片段的 z 值;如果没有通过,会丢弃该片段。如果启用了深度缓冲,应该在每个渲染迭代之前使用 GL_DEPTH_BUFFER_BIT 来清除深度缓冲,否则会使用上一次渲染迭代中的写入的深度值。
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);某些情况下需要对所有片段都执行深度测试并丢弃相应的片段,但不希望更新深度缓冲,禁用深度缓冲的写入。
glDepthMask(GL_FALSE); // 深度测试被启用才有效。OpenGL 允许修改深度测试使用的比较运算符,来控制什么时候该通过或丢弃一个片段,什么时候更新深度缓冲。
glDepthFunc(GL_LESS); // 默认使用
- GL_ALWAYS:永远通过深度测试
- GL_NEVER:永远不通过深度测试
- GL_LESS:在片段深度值小于缓冲的深度值时通过测试
- GL_EQUAL:在片段深度值等于缓冲区的深度值时通过测试
- GL_LEQUAL: 在片段深度值小于等于缓冲区的深度值时通过测试
- GL_GREATER:在片段深度值大于缓冲区的深度值时通过测试
- GL_NOTEQUAL:在片段深度值不等于缓冲区的深度值时通过测试
- GL_GEQUAL:在片段深度值大于等于缓冲区的深度值时通过测试
下面的线性方程将 z 值变换到了[0,1]之间的深度值: \[
depth = \frac{z-near}{far-near}
\]
将非常近的物体的深度值设置为接近 0,非常接近远平面的的深度值会非常接近1。
实际使用时,需要 z 很小(距离很近)的时候提供较大的精度值,需要一个非线性变换: \[ depth = \frac{z^{-1}-near^{-1}}{far^{-1}-near^{-1}} \] 深度缓冲中的值在屏幕空间中不是线性的(下面是 near = 0.1、far = 100 的图像):
near = 0.1
far = 100
z = np.arange(0.1, 100, 0.1)
depth = (1 / z - 1 / near) / (1 / far - 1 / near)
plt.plot(z, depth)
深度值很大一部分是由很小的 z 值所决定的,这给了近处的物体很大的深度精度。
内建 gl_FragCoord 向量的 z 值包含了那个特定片段的深度值,可以可视化深度值。
FragColor = vec4(vec3(gl_FragCoord.z), 1.0);两个平面或三角形非常紧密地平行排列在一起时会发生深度冲突(Z-fighting)。深度缓冲没有足够的精度来决定两个形状哪个在前面,结果就不断地在切换前后顺序,导致奇怪现象。解决方法如下:
- 不要把多个物体摆得太靠近,防止一些三角形重叠。
- 将近平面设置远一些。
- 使用更高精度的深度缓冲。
Stencil Test
当片段着色器处理完一个片段之后,模板测试(Stencil Test)会开始执行;模板测试可能会丢弃片段,保留的片段会进入深度测试。
模板测试是根据模板缓冲(Stencil Buffer)进行的。每个模板值(Stencil Value)是8位的,可以将这些模板值设置为想要的值,然后当某一个片段有某一个模板值的时候,就可以选择丢弃或保留这个片段。
每个窗口库都需要配置一个模板缓冲。GLFW自动做了这件事,,其它窗口库可能不会默认创建一个模板库。

模板缓冲首先被清除为 0,之后在模板缓冲中使用1填充了部分,场景中片段只在片段的模板值为1的时候被渲染。
启用 GL_STENCIL_TEST 来启用模板测试:
glEnable(GL_STENCIL_TEST);在每次迭代之前清除模板缓冲:
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);glStencilMask 设置一个位掩码(Bitmask),与将要写入缓冲的模板值进行与(AND)运算:
glStencilMask(0xFF); // 每一位写入模板缓冲时都保持原样
glStencilMask(0x00); // 每一位在写入模板缓冲时都会变成0(禁用写入)glStencilFunc(GLenum func, GLint ref, GLuint mask);
func:设置模板测试函数,会应用到已储存的模板值和glStencilFunc函数的ref值上,可用函数与深度缓冲类似。ref:模板测试的参考值,模板缓冲的内容将会与这个值进行比较。mask:会与参考值和储存的模板值在测试比较它们之前进行与(AND)运算,默认所有位都为 1。
上面的例子中:片段的模板值等于(GL_EQUAL)参考值 1,会通过测试被绘制,否则被丢弃。
glStencilFunc(GL_EQUAL, 1, 0xFF);glStencilOp(GLenum sfail, GLenum dpfail, GLenum dppass);
// 默认: glStencilOp(GL_KEEP, GL_KEEP, GL_KEEP);
sfail:模板测试失败时采取的行为。dpfail:模板测试通过,但深度测试失败时采取的行为。dppass:模板测试和深度测试都通过时采取的行为。
行为 描述 GL_KEEP 保持当前储存的模板值 GL_ZERO 将模板值设置为0 GL_REPLACE 将模板值设置为 glStencilFunc函数设置的ref值GL_INCR 如果模板值小于最大值则将模板值加1 GL_INCR_WRAP 与GL_INCR一样,但如果模板值超过了最大值则归零 GL_DECR 如果模板值大于最小值则将模板值减1 GL_DECR_WRAP 与GL_DECR一样,但如果模板值小于0则将其设置为最大值 GL_INVERT 按位翻转当前的模板缓冲值
物体边框
创建一个边框颜色片段着色器:
FragColor = vec4(0.26, 0.12, 0.34, 1.0);启用模板测试
glEnable(GL_STENCIL_TEST);
glStencilFunc(GL_NOTEQUAL, 1, 0xFF);
glStencilOp(GL_KEEP, GL_KEEP, GL_REPLACE);
- 模板测试和深度测试有一个测试失败:保留当前储存在模板缓冲中的值。
- 模板测试和深度测试都通过:储存的模板值设置为参考值,用
glStencilFunc设置为 1。
在 rendering loop 中清除模板缓冲。
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);绘制不需要边框的物体:( 禁用模板缓冲,不更新)
shader.active();
glStencilMask(0x00);
glBindVertexArray(planeVAO);
glBindTexture(GL_TEXTURE_2D, texturePlane);
shader.setMat4("model", glm::mat4(1.0f));
glDrawArrays(GL_TRIANGLES, 0, 6);
glBindVertexArray(0);绘制需要边框的物体:(将模板缓冲清除为0,对所有绘制的片段,将模板值更新为1)
shader.active();
// 所有的片段都更新模板缓冲
glStencilFunc(GL_ALWAYS, 1, 0xFF);
// 启用模板缓冲写入
glStencilMask(0xFF);
glBindVertexArray(cubeVAO);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, textureCube);
model = glm::translate(model, glm::vec3(-1.0f, 0.0f, -1.0f));
shader.setMat4("model", model);
glDrawArrays(GL_TRIANGLES, 0, 36);使用 GL_ALWAYS 模板测试函数,保证需要绘制物体的每个片段都会将模板缓冲的模板值更新为1。
绘制放大的物体:(禁用模板写入和深度测试)
border_shader.active();
glStencilFunc(GL_NOTEQUAL, 1, 0xFF);
glStencilMask(0x00);
glDisable(GL_DEPTH_TEST);
float scale = 1.1;
glBindVertexArray(cubeVAO);
glBindTexture(GL_TEXTURE_2D, textureCube);
model = glm::mat4(1.0f);
model = glm::translate(model, glm::vec3(-1.0f, 0.0f, -1.0f));
model = glm::scale(model, glm::vec3(scale, scale, scale));
border_shader.setMat4("model", model);
glDrawArrays(GL_TRIANGLES, 0, 36);使用 GL_NOTEQUAL模板测试函数,保证只绘制需要绘制边框的物体的模板值不为 1 的部分。
禁用深度测试,让放大的地方(边框),不会被不需要绘制边框的物体覆盖。
重启深度缓冲和模板测试:
glStencilMask(0xFF);
glStencilFunc(GL_ALWAYS, 0, 0xFF);
glEnable(GL_DEPTH_TEST);下面是测试的情况:

Blending
透明是由 alpha 值来控制的。
片段丢弃
使用 RGBA 加载含 alpha 通道的图像,在着色器中简单判断一下就行。
vec4 texColor = texture(texture1, TexCoords);
if(texColor.a < 0.1)
discard;
FragColor = texColor;OpenGL 默认不知道怎么处理 alpha 值,不知道什么时候丢弃片段。
discard指令被调用,会保证片段不会被进一步处理,不会进入颜色缓冲。能够在片段着色器中检测一个片段的 alpha 值是否低于某个阈值,满足条件就丢弃这个片段,
使用透明值,纹理图像的顶部将会与底部边缘的纯色值进行插值,结果是一个半透明的有色边框。
使用 alpha 纹理时,环绕方式设置为 GL_CLAMP_TO_EDGE。
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, format == GL_RGBA ? GL_CLAMP_TO_EDGE : GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, format == GL_RGBA ? GL_CLAMP_TO_EDGE : GL_REPEAT); 
颜色混合
启用 GL_BLEND 来启用混合。
glEnable(GL_BLEND);\[ C_{RES}=C_{SRC}*P_{SRC}+C_{DST}*P_{DST} \]
- \(C_{SRC}\):纹理颜色向量。
- \(P_{SRC}\):alpha 值对\(C_{SRC}\)的影响。
- \(C_{DST}\):颜色缓冲中的颜色向量。
- \(P_{DST}\):alpha 值对\(C_{DST}\)的影响。
用下面的函数设置上面的参数。(glBlendColor 设置颜色常量 \(C_{CONST}\))
glBlendFunc(GLenum sfactor, GLenum dfactor);
- GL_ZERO:\(0\)
- GL_ONE:\(1\)
- GL_SRC_COLOR:\(C_{SRC}\)
- GL_ONE_MINUS_SRC_COLOR:\(1-C_{SRC}\)
- GL_DST_COLOR:\(C_{DST}\)
- GL_ONE_MINUS_DST_COLOR:\(1-C_{DST}\)
- GL_SRC_ALPHA:\(C_{SRC}.{\alpha}\)
- GL_ONE_MINUS_SRC_ALPHA:\(1-C_{SRC}.{\alpha}\)
- GL_DST_ALPHA:\(C_{DST}.{\alpha}\)
- GL_ONE_MINUS_DST_ALPHA:\(1-C_{DST}.{\alpha}\)
- GL_CONSTANT_COLOR:\(C_{CONST}\)
- GL_ONE_MINUS_CONSTANT_COLOR:\(1-C_{CONST}\)
- GL_CONSTANT_ALPHA:\(C_{CONST}.{\alpha}\)
- GL_ONE_MINUS_CONSTANT_ALPHA:\(1-C_{CONST}.{\alpha}\)
比如\(P_{SRC} = C_{SRC}.{\alpha},~~ P_{DST} = 1-C_{SRC}.{\alpha}\)
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);使用 glBlendFuncSeparate 为 RGB 和 alpha 通道设置不同的选项:
glBlendFuncSeparate(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA, GL_ONE, GL_ZERO);glBlendEquation(GLenum mode)允许设置运算符
- GL_FUNC_ADD:默认。
- GL_FUNC_SUBTRACT:相减。
- GL_FUNC_REVERSE_SUBTRACT:交换再相减。
半透明纹理
始化时启用混合,并设定相应的混合函数:
glEnable(GL_BLEND);
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);启用了混合,不需要丢弃片段,把片段着色器还原:
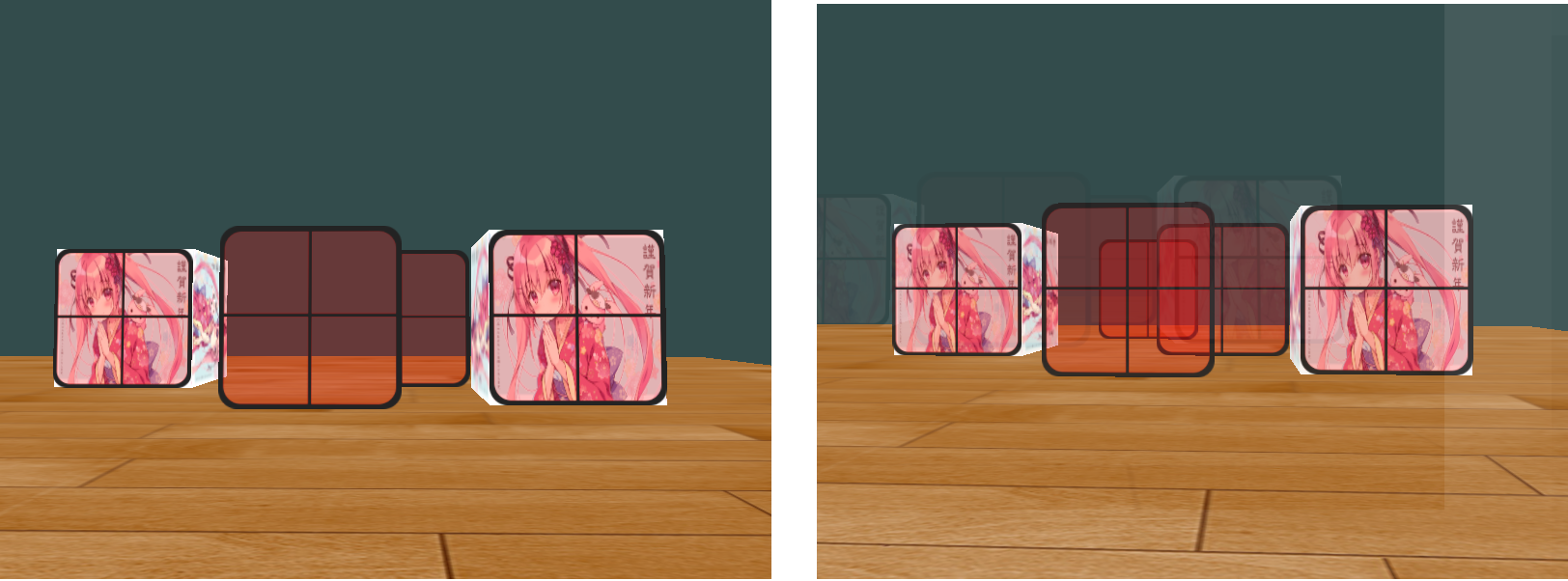
FragColor = texture(texture1, TexCoords);注意到最前面的窗户遮挡了后面的窗户(下图左)。
深度测试和混合一起使用,当写入深度缓冲时,深度缓冲不会检查片段是否是透明,所以透明部分会和其它值一样写入到深度缓冲中。即使透明的部分应该显示背后的窗户,深度测试仍然丢弃了它们。
对于草贴图这种全透明的物体,可以选择丢弃透明的片段而不是混合它们,这样就没有深度问题。
绘制一个有不透明和透明物体的场景顺序:
- 绘制所有不透明物体。
- 观察者视角获取物体的距离,对所有透明物体按距离排序。
- 按顺序绘制所有透明物体(先绘制远处的)。
std::map<float, glm::vec3> _map;
glBindVertexArray(windowVAO);
glBindTexture(GL_TEXTURE_2D, textureWindow);
for (int i = 0; i < arraySize(window_pos); i++)
{
_map[glm::length(camera.getPosition() - window_pos[i])] = window_pos[i];
}
for (auto&& it = _map.rbegin(); it != _map.rend(); ++it)
{
model = glm::mat4(1.0f);
model = glm::translate(model, it->second);
shader.setMat4("model", model);
glDrawArrays(GL_TRIANGLES, 0, 6);
}
glBindVertexArray(0);
- map 会按照 Key 对值排序(小到大)。
- 逆序遍历 map,auto 实际上是
std::map<float,glm::vec3>::reverse_iterator,绘制物体。
Face culling
只渲染观察者能看到的面,丢弃剩下的面;何一个面都有两侧,面向和背对观察者的面,只绘制面向观察者的面。
OpenGL 能检查所有面向(Front Facing)观察者的面,并渲染它们;丢弃那些背向(Back Facing)的面,节省片段着色器调用(开销很大)。OpenGL使用了一个技巧,分析顶点数据的环绕顺序。
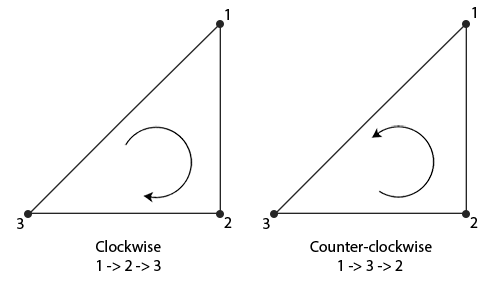
下面是按照顺时针和逆时针定义的三角形:
float vertices[] = { // 顺时针 vertices[0], // 1 vertices[1], // 2 vertices[2], // 3 // 逆时针 vertices[0], // 1 vertices[2], // 3 vertices[1] // 2 };
默认环绕顺序为逆时针定义的三角形为正向三角形(观察者看过去为逆时针)。
会剔除所有顺时针渲染的面(背向观察者的面)。
启用 OpenGL 的 GL_CULL_FACE 选项来开启面剔除。
glEnable(GL_CULL_FACE);只对立方体这样的封闭形状有效,绘制草之类的物体,要禁用面剔除,因为其正向面和背向面都应该可见。
调用 glCullFace 改变需要剔除的面的类型。
GL_BACK:只剔除背面(默认)。GL_FRONT:只剔除正面。GL_FRONT_AND_BACK:剔除正面和背面。
将顺时针的面定义为正向面:
glFrontFace(GL_CW); // 默认GL_CCW代表是逆时针面剔除可以很好的提高程序性能,但应该明确什么物体应该面剔除,什么物体禁止面剔除。
FrameBuffers
帧缓冲FrameBuffers = 颜色缓冲ColorBuffers + 深度缓冲DepthBuffer + 模板缓冲StencilBuffer
目前的操作都是在默认帧缓冲的渲染缓冲上进行的,默认的帧缓冲是在创建窗口的时候生成和配置的。
使用 glGenFramebuffers 创建帧缓冲对象FBO(Frame Buffer Object)。
unsigned FBO;
glGenFramebuffers(1, &FBO);使用 glBindFramebuffer 绑定帧缓冲。
glBindFramebuffer(GL_FRAMEBUFFER, FBO);绑定到 GL_FRAMEBUFFER 目标之后,所有读取和写入帧缓冲的操作将会影响当前绑定的帧缓冲。
可以使用 GL_READ_FRAMEBUFFER 或 GL_DRAW_FRAMEBUFFER一个帧缓冲分别绑定到读取或写入目标。
- 绑定到 GL_READ_FRAMEBUFFER 的帧缓冲将会使用在读取操作中。
- 绑定到 GL_DRAW_FRAMEBUFFER 的帧缓冲将会被用作渲染、清除等写入操作的目标。
大部分情况不需要区分,使用 GL_FRAMEBUFFER 绑定。
完整的帧缓冲
- 至少有一个缓冲(颜色、深度、模板缓冲)。
- 至少有一个颜色附件(Attachment)。
- 所有的附件都必须是完整的(保留了内存)。
- 每个缓冲都应该有相同的样本数。
下面的代码可以判断帧缓冲是否完整:
if(glCheckFramebufferStatus(GL_FRAMEBUFFER) == GL_FRAMEBUFFER_COMPLETE)之后所有的渲染操作将会渲染到当前绑定帧缓冲的附件中。
当前绑定的帧缓冲不是默认帧缓冲,渲染指令不会对窗口的视觉输出有任何影响。渲染到一个不同帧缓冲即离屏渲染(Off-screen Rendering)。要让所有渲染操作在主窗口中有视觉效果,要再次激活默认帧缓冲,并绑定到 0。
glBindFramebuffer(GL_FRAMEBUFFER, 0);完成所有的帧缓冲操作之后,要删除这个帧缓冲对象。
glDeleteFramebuffers(1, &FBO);附件是一个内存位置,它能作为帧缓冲的一个缓冲。
当创建一个附件的时候有两个选项:纹理或渲染缓冲对象(Renderbuffer Object)。
纹理附件
把一个纹理附加到帧缓冲,所有渲染指令会写入到这个纹理中。使用纹理的优点是,可以把所有渲染操作的结果将会被储存在一个纹理图像中,可以在着色器中很方便地使用。
unsigned texture;
glGenTextures(1, &texture);
glBindTexture(GL_TEXTURE_2D, texture);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 800, 600, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
- 维度设置为了屏幕大小(不是必须的)。
- data 参数设置为 NULL,仅仅分配内存而不填充。
- 大多数情况下不需要关心环绕方式或多级渐远纹理。
- 要屏幕渲染到一个更小或更大的纹理上,需要在渲染到帧缓冲之前再次调用冲
glViewport,使用纹理的新维度作为参数,否则只有小部分的纹理或屏幕会被渲染到这个纹理上。
附加到帧缓冲上:
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, texture, 0);
- param1:target 帧缓冲的目标(绘制、读取)。
- param2:attachment 件类型(可以添加多个),这里是颜色附件。
- param3:textarget 附加的纹理类型。
- param4:texture 附加的纹理本身。
- param5:level 多级渐远纹理的级别(保留0)。
附加一个深度缓冲纹理:
- 附件类型:GL_DEPTH_ATTACHMENT
- 纹理格式(Format)、内部格式(Internalformat):GL_DEPTH_COMPONENT
附加一个深度模板纹理:
- 附件类型: GL_STENCIL_ATTACHMENT
- 纹理格式(Format)、内部格式(Internalformat):GL_STENCIL_INDEX
可以将深度缓冲和模板缓冲附加为一个单独的纹理。
glTexImage2D(GL_TEXTURE_2D, 0, GL_DEPTH24_STENCIL8, 800, 600, 0,
GL_DEPTH_STENCIL,GL_UNSIGNED_INT_24_8,NULL);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_TEXTURE_2D, texture, 0);渲染缓冲对象
渲染缓冲对象(RenderBuffer Object)是一个真正的缓冲,即一系列的字节、整数、像素,它会将数据储存为 OpenGL 原生渲染格式,是为离屏渲染到帧缓冲优化过的。
创建一个渲染缓冲对象。
unsigned RBO;
glGenRenderbuffers(1, &RBO);绑定渲染缓冲对象。
glBindRenderbuffer(GL_RENDERBUFFER, RBO);由于渲染缓冲对象通常是只写的,会经常用于深度和模板附件,因为一般不需要从深度和模板缓冲中读取值,只关心深度和模板测试。
用 glRenderbufferStorage 创建深度和模板缓冲。
创建一个渲染缓冲对象是专门被设计作为图像使用的,而不是纹理作为通用数据缓冲。
这里选择 GL_DEPTH24_STENCIL8 作为内部格式,它封装了 24 位的深度和 8 位的模板缓冲。
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH24_STENCIL8, 800, 600);附加这个渲染缓冲对象。
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, RBO);渲染到纹理
这里将场景渲染到一个附加到帧缓冲对象上的颜色纹理中,在整个屏幕的四边形上绘制这个纹理。
需要一个覆盖屏幕的平面和平面 VAO:
float surface[] =
{
// positions // texCoords
-1.0f, 1.0f, 0.0f, 1.0f,
-1.0f, -1.0f, 0.0f, 0.0f,
1.0f, -1.0f, 1.0f, 0.0f,
-1.0f, 1.0f, 0.0f, 1.0f,
1.0f, -1.0f, 1.0f, 0.0f,
1.0f, 1.0f, 1.0f, 1.0f
};
unsigned int surfaceVAO, surfaceVBO;
glGenVertexArrays(1, &surfaceVAO);
glGenBuffers(1, &surfaceVBO);
glBindVertexArray(surfaceVAO);
glBindBuffer(GL_ARRAY_BUFFER, surfaceVBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(surface), &surface, GL_STATIC_DRAW);
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 2, GL_FLOAT, GL_FALSE, 4 * sizeof(float), (void*)0);
glEnableVertexAttribArray(1);
glVertexAttribPointer(1, 2, GL_FLOAT, GL_FALSE, 4 * sizeof(float), (void*)(2 * sizeof(float)));
glBindVertexArray(0);创建一个帧缓冲对象:
unsigned FBO;
glGenFramebuffers(1, &FBO);
glBindFramebuffer(GL_FRAMEBUFFER, FBO);创建一个纹理图像并绑定到当前帧缓冲对象:
unsigned TBO;
glGenTextures(1, &TBO);
glBindTexture(GL_TEXTURE_2D, TBO);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 800, 600, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glBindTexture(GL_TEXTURE_2D, 0);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, TBO, 0);创建一个渲染缓冲对象让OpenGL 能够进行深度测试(模板测试):
unsigned RBO;
glGenRenderbuffers(1, &RBO);
glBindRenderbuffer(GL_RENDERBUFFER, RBO);
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH24_STENCIL8, 800, 600);
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, RBO);
if (glCheckFramebufferStatus(GL_FRAMEBUFFER) != GL_FRAMEBUFFER_COMPLETE)
m_log("Framebuffer can't complete.");解绑帧缓冲:
glBindFramebuffer(GL_FRAMEBUFFER, 0);创建简单着色器绘制四边形屏幕:
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec2 aTexCoords;
out vec2 TexCoords;
void main()
{
gl_Position = vec4(aPos.x, aPos.y, 0.0, 1.0);
TexCoords = aTexCoords;
}
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
uniform sampler2D surfaceTexture;
void main()
{
FragColor = texture(surfaceTexture, TexCoords);
}in rendering loop:
// 绑定帧缓冲
glBindFramebuffer(GL_FRAMEBUFFER, FBO)
glClearColor(0.2f, 0.3f, 0.3f, 1.0f);
//glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glEnable(GL_DEPTH_TEST);
// 绘制场景中的物体到帧缓冲中,绘制代码不变(之前绘制到默认帧缓冲中)
// 解绑帧缓冲并清除
glBindFramebuffer(GL_FRAMEBUFFER, 0);
glClearColor(1.0f, 1.0f, 1.0f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT);
// 绘制屏幕
surface_shader.active();
glBindVertexArray(surfaceVAO);
glDisable(GL_DEPTH_TEST);
glBindTexture(GL_TEXTURE_2D, TBO);
glDrawArrays(GL_TRIANGLES, 0, 6);
glBindVertexArray(0); 下图是效果(右边是线框模式,可以看出只绘制了两个三角形)。
后期处理
负片:
FragColor = vec4(1.0 - vec3(texture(surfaceTexture, TexCoords)), 1.0);灰度:
vec3 t = texture(surfaceTexture, TexCoords).rgb;
float gray = 0.2126 * t.r + 0.7152 * t.g + 0.0722 * t.b;
FragColor = vec4(gray, gray, gray, 1.0);锐化(Sharpen)核:
大部分核将所有权重加起来之后都应该会等于1,如果不等于1,最终的纹理颜色将会比原来更亮或者更暗。
核在对屏幕纹理的边缘进行采样的时候,还会对中心像素周围的 8 个像素进行采样,会取到纹理之外的像素。环绕方式默认是 GL_REPEAT,在没有设置的情况下取到的是屏幕另一边的像素,而另一边的像素本不应该对中心像素产生影响。因此可以将屏幕纹理的环绕方式设置为 GL_CLAMP_TO_EDGE。在取到纹理外的像素时,能重复边缘的像素来更精确地估计最终的值。
const float offset = 1.0 / 300.0;
const vec2 offsets[9] =
{
vec2(-offset, offset), vec2( 0.0f, offset), vec2( offset, offset),
vec2(-offset, 0.0f), vec2( 0.0f, 0.0f), vec2( offset, 0.0f),
vec2(-offset, -offset), vec2( 0.0f, -offset), vec2( offset, -offset)
};
const float kernel[9] =
{
-1, -1, -1,
-1, 9, -1,
-1, -1, -1
};
void main()
{
vec3 sampleTex[9];
for(int i = 0; i < 9; i++)
{
sampleTex[i] = vec3(texture(surfaceTexture, TexCoords.st + offsets[i]));
}
vec3 col = vec3(0.0);
for(int i = 0; i < 9; i++)
col += sampleTex[i] * kernel[i];
FragColor = vec4(col, 1.0);
}模糊核:
const float kernel[9] =
{
1.0 / 16, 2.0 / 16, 1.0 / 16,
2.0 / 16, 4.0 / 16, 2.0 / 16,
1.0 / 16, 2.0 / 16, 1.0 / 16
};边缘检测(Edge-detection)核:
const float kernel[9] =
{
1, 1, 1,
1, -8, 1,
1, 1, 1
};Soble边缘检测:
// 水平梯度/垂直轮廓
const float kernel[9] =
{
-1, 0, 1,
-2, 0, 2,
-1, 0, 1,
};
// 垂直梯度/水平轮廓
const float kernel[9] =
{
-1,-2, -1,
-0, 0, 0,
-1, 2, 1,
};
Cubemap
立方体贴图(Cubemap)是一个有 6 个 2D 纹理的纹理。
立方体贴图创建要绑定到 GL_TEXTURE_CUBE_MAP。
unsigned cubemap;
glGenTextures(1, &cubemap);
glBindTexture(GL_TEXTURE_CUBE_MAP, cubemap);调用 glTexImage2D 函数 6 次为每个面添加贴图。OpenGL 提供 6 个特殊纹理目标,对应立方体贴图的 6 个面。
- GL_TEXTURE_CUBE_MAP_POSITIVE_X 右
- GL_TEXTURE_CUBE_MAP_NEGATIVE_X 左
- GL_TEXTURE_CUBE_MAP_POSITIVE_Y 上
- GL_TEXTURE_CUBE_MAP_NEGATIVE_Y 下
- GL_TEXTURE_CUBE_MAP_POSITIVE_Z 后
- GL_TEXTURE_CUBE_MAP_NEGATIVE_Z 前
下面是加载立方体贴图的函数实现:
unsigned m_load_img3D(const char* paths[], const size_t N = 6, bool flip_verticlal = false)
{
unsigned texture;
glGenTextures(1, &texture);
glBindTexture(GL_TEXTURE_CUBE_MAP, texture);
stbi_set_flip_vertically_on_load(flip_verticlal);
int width, height, channels;
for (int i = 0; i < N; i++)
{
unsigned char* data = stbi_load(paths[i], &width, &height, &channels, 0);
if (data)
{
GLenum format = get_format(channels);
glTexImage2D(GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, 0, format, width, height, 0, format, GL_UNSIGNED_BYTE, data);
stbi_image_free(data);
}
else
{
stbi_image_free(data);
#ifdef USE_LOG
m_log("Failed to load texture!");
m_log(paths[i]);
#endif
}
}
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_R, GL_CLAMP_TO_EDGE);
return texture;
}渲染天空盒小优化
先渲染天空盒,会对屏幕上的每一个像素运行一遍片段着色器,即使只有小部分的天空盒最终是可见的。
最后渲染天空盒,深度缓冲会填充满所有物体的深度值,只需要在提前深度测试通过的地方渲染天空盒的片段就可以了,减少了片段着色器的调用。
问题是,天空盒只是一个 1x1x1 的立方体,会不通过大部分的深度测试,导致渲染失败。
注意到透视除法是在顶点着色器运行之后执行的,将
gl_Position的xyz坐标除以w分量,结果z分量是顶点深度值。让输出的z分量等于w分量,当执行透视除法后,z分量会变为w / w = 1.0,即最大的深度值,天空盒只会在没有可见物体的地方渲染。(samplerCube用于片段着色器采样立方体贴图)#version 330 core layout (location = 0) in vec3 aPos; out vec3 TexCoords; uniform mat4 projection; uniform mat4 view; void main() { TexCoords = aPos; vec4 pos = projection * view * vec4(aPos, 1.0); gl_Position = pos.xyww; } #version 330 core out vec4 FragColor; in vec3 TexCoords; uniform samplerCube skybox; void main() { FragColor = texture(skybox, TexCoords); }深度缓冲将会填充上天空盒1.0 的值,深度函数从默认的 GL_LESS 改为GL_LEQUAL,保证天空盒在值小于或等于深度缓冲而不是小于时通过深度测试,渲染完成后改回 GL_LESS 。
glDepthFunc(GL_LEQUAL); skybox_shader.active(); view = glm::mat4(glm::mat3(camera.getViewMat())); skybox_shader.setMat4("view", view); skybox_shader.setMat4("projection", projection); glBindVertexArray(skyboxVAO); glActiveTexture(GL_TEXTURE0); glBindTexture(GL_TEXTURE_CUBE_MAP, skybox_cubemap); glDrawArrays(GL_TRIANGLES, 0, 36); glBindVertexArray(0); glDepthFunc(GL_LESS);不希望移动影响天空盒子,因此设置矩阵第四个维度为0。
view = glm::mat4(glm::mat3(camera.getViewMat()));

反射
在物体的片段着色器上,根据观察向量 D、物体法向量 N 来计算反射向量 R。( reflect 函数)
需要物体有法向量,并更新物体的顶点着色器和片段着色器。
Position 输出向量是一个世界空间的位置向量,用来在片段着色器内计算观察方向向量。
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aNormal;
out vec3 Normal;
out vec3 Position;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
void main()
{
Normal = mat3(transpose(inverse(model))) * aNormal;
Position = vec3(model * vec4(aPos, 1.0));
gl_Position = projection * view * model * vec4(aPos, 1.0);
}
#version 330 core
out vec4 FragColor;
in vec3 Normal;
in vec3 Position;
uniform vec3 cameraPos;
uniform samplerCube skybox;
void main()
{
vec3 D = normalize(Position - cameraPos);
vec3 R = reflect(D, normalize(Normal));
FragColor = vec4(texture(skybox, R).rgb, 1.0);
}渲染物体之前要绑定立方体贴图:
glBindVertexArray(mirrorVAO);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_CUBE_MAP, skybox_cubemap);
glDrawArrays(GL_TRIANGLES, 0, 36);
glBindVertexArray(0);
不需要改变 skybox。
折射
修改下片段着色器即可。(refract 函数)
float refractive_index = 1.00 / 1.55;
vec3 D = normalize(Position - cameraPos);
vec3 R = refract(D, normalize(Normal), refractive_index);
FragColor = vec4(texture(skybox, R).rgb, 1.0);Buffer
OpenGL 的缓冲是管理特定内存块的对象,需要绑定到对应的缓冲目标。
- 绑定到 GL_ARRAY_BUFFER:顶点数组缓冲。
- 绑定到 GL_ELEMENT_ARRAY_BUFFER:顶点索引缓冲。
OpenGL内部会为每个目标储存一个缓冲,根据目标的不同,以不同的方式处理缓冲。
数据导入缓冲区
glBufferData :填充缓冲对象所管理的内存,如果设置 data 为 NULL,只分配内存,不进行填充。
glBufferSubData填充缓冲特定区域:
- 可以指定偏移量。
- 确保有足够的内存分配(先调用
glBufferData)。
glBufferSubData(GL_ARRAY_BUFFER, 1 << 4, sizeof(data), &data); //[16, 16 + sizeof(data)]调用 glMapBuffer 函数返回当前绑定缓冲的内存指针:
// 绑定缓冲区
glBindBuffer(GL_ARRAY_BUFFER, VBO);
// 获取
void *ptr = glMapBuffer(GL_ARRAY_BUFFER, GL_WRITE_ONLY);
// 内存拷贝
memcpy(ptr, data, sizeof(data));
// 解除内存指针绑定,ptr不再可用
glUnmapBuffer(GL_ARRAY_BUFFER);直接映射数据到缓冲(比如从文件中读取数据,并直接复制到内存缓冲中),可以用
glMapBuffer。
顶点属性分批
const float positions[] = {};
const float normals[] = {};
const float texCoords[] = {};
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(positions), &positions);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions), sizeof(normals), &normals);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions) + sizeof(normals),
sizeof(texCoords), &texCoords);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), 0);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)(sizeof(positions)));
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float),
(void*)(sizeof(positions) + sizeof(normals)));缓冲复制
使用 glCopyBufferSubData 把一个缓冲中的数据复制到另一个缓冲中:
void glCopyBufferSubData(GLenum readtarget, GLenum writetarget,
GLintptr readoffset, GLintptr writeoffset, GLsizeiptr size);
- readtarget:源缓冲目标(比如 VERTEX_ARRAY_BUFFER)。
- writetarget:目标缓冲目标(比如 VERTEX_ELEMENT_ARRAY_BUFFER)。
- readoffset:源偏移量。
- writeoffset:目标偏移量。
- size:数据大小。
读写数据的两个不同缓冲都为顶点数组缓冲:GL_COPY_READ_BUFFER 和 GL_COPY_WRITE_BUFFER。
const float vertex_data[] = {};
// 1
glBindBuffer(GL_COPY_READ_BUFFER, VBO1);
glBindBuffer(GL_COPY_WRITE_BUFFER, VBO2);
glCopyBufferSubData(GL_COPY_READ_BUFFER, GL_COPY_WRITE_BUFFER, 0, 0, sizeof(vertex_data));
// 2
glBindBuffer(GL_ARRAY_BUFFER, VBO1);
glBindBuffer(GL_COPY_WRITE_BUFFER, VBO2);
glCopyBufferSubData(GL_ARRAY_BUFFER, GL_COPY_WRITE_BUFFER, 0, 0, sizeof(vertex_data));Advanced GLSL
内建变量(Built-in Variable)
顶点着色器:
gl_Position:(输出变量)裁剪空间输出位置向量。
gl_PointSize:(输出变量)顶点着色器中修改点大小的功能默认是禁用的,启用方法如下:
glEnable(GL_PROGRAM_POINT_SIZE);点的大小设置为裁剪空间位置的 z 值,即顶点距观察者的距离,它会随着观察者距顶点距离变远而变大。
gl_Position = projection * view * model * vec4(aPos, 1.0); gl_PointSize = gl_Position.z;这个可以用来做粒子特效。
gl_VertexID:(输入变量)储存了正在绘制的顶点 ID。
片段着色器:
gl_FragCoord:(只读变量)在片段着色器中,x、y 为片段屏幕空间坐标,z 是片段深度值。
可以对比不同片段计算的视觉输出效果。
gl_FrontFacing:当前片段是属于正向面的一部分还是背向面的一部分。
可以用来输出正面和背面不同的效果。
gl_FragDepth:在着色器内设置片段深度值,会禁用所有的提前深度测试。
OpenGL 4.2 起,在片段着色器的顶部使用深度条件重新声明 gl_FragDepth 变量:
layout (depth_<condition>) out float gl_FragDepth;
- any:默认值,禁用提前深度测试,会损失很多性能。
- greater:只能让深度值比
gl_FragCoord.z更大。- less:只能让深度值比
gl_FragCoord.z更小。- unchanged:要写入
gl_FragDepth,只能写入gl_FragCoord.z的值。
接口块
用 in 或 out 关键字来定义。只要两个接口块的名字一样,对应的输入和输出会匹配起来。
out VS_OUT
{
vec2 TexCoords;
vec3 Normal;
} vs_out;
in VS_OUT
{
vec2 TexCoords;
vec3 Normal;
} fs_in;uniform缓冲对象(Uniform Buffer Object)
UBO 允许定义一系列在多个着色器中相同的全局Uniform变量,使用 UBO 只需要设置相关uniform 一次。
UBO 是一个缓冲,使用 glGenBuffers 创建,绑定到 GL_UNIFORM_BUFFER 缓冲目标。
使用顶点着色器,将 projection 和 view 存储到 Uniform 块中:
layout (std140) uniform Matrices
{
mat4 projection;
mat4 view;
};之前在每个渲染迭代中,对每个着色器设置 projection 和 view 的 Uniform 矩阵。
利用 UBO,只需要存储这些矩阵一次。声明了 Matrices 的 Uniform 块,Uniform 块中的变量可以直接访问,不需要加块名为前缀。OpenGL 代码中将矩阵值存入缓冲中,每个声明了这个Uniform 块的着色器都能够访问这些矩阵。
Uniform 块的内容是储存在一个缓冲对象中的,实际上只是一块预留内存。需要告诉 OpenGL 内存的哪一部分对应着色器中的哪一个 uniform 变量。
layout (std140)当前定义的 Uniform 块对它的内容使用一个特定的内存布局。std140 布局声明了每个变量的偏移量都是由一系列规则所决定的,声明了每个变量类型的内存布局。td140 布局不是最高效的布局,但保证了内存布局在每个声明了这个 Uniform 块的程序中是一致的。
还有
shared和packed布局,这里不赘述。
基准对齐量(Base Alignment)等于一个变量在 Uniform 块中所占据的空间(包括填充量(Padding))。
对齐偏移量(Aligned Offset)是一个变量从块起始位置的字节偏移量,必须是基准对齐量的倍数。
每个变量(int、float和bool)被定义为 4 字节量,令 N = 4 。
- 标量:基准对齐量 N。
- 向量:2N 或 4N(vec3)。
- 标量数组或向量数组:与 vec4 相同。
- 矩阵:储存为列向量的数组,向量基准对齐量与 vec4 相同。
- 结构体:所有元素根据规则计算后的大小,会填充到 vec4 大小的倍数。
layout (std140) uniform M_Block
{ // total 152
// 基准对齐量 // 对齐偏移量
float value; // 4 // 0
vec3 vector; // 16 // 16 (16的倍数,所以 4->16)
mat4 matrix; // 16 // 32 (列 0)
// 16 // 48 (列 1)
// 16 // 64 (列 2)
// 16 // 80 (列 3)
float values[3]; // 16 // 96 (values[0])
// 16 // 112 (values[1])
// 16 // 128 (values[2])
bool boolean; // 4 // 144
int integer; // 4 // 148
}; 使用 UBO,调用 glGenBuffers 创建 UBO,并绑定到 GL_UNIFORM_BUFFER,再用 glBufferData 分配内存。
unsigned UBO;
glGenBuffers(1, &UBO);
glBindBuffer(GL_UNIFORM_BUFFER, UBO);
glBufferData(GL_UNIFORM_BUFFER, 152, NULL, GL_STATIC_DRAW);
glBindBuffer(GL_UNIFORM_BUFFER, 0);需要对缓冲更新或者插入数据,绑定到对应 UBO,用 glBufferSubData更新内存。
在 OpenGL 上下文中,定义了一些绑定点(Binding Point),可以将一个 Uniform 缓冲链接至它,并将着色器中的Uniform 块绑定到相同的绑定点,把它们连接到一起。
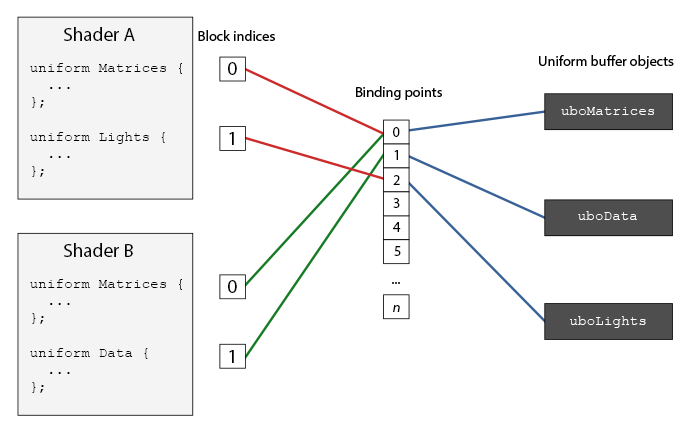
将图中的 Lights Uniform 块链接到绑定点2:(需要对每个着色器重复这一步骤)
unsigned lights_index = glGetUniformBlockIndex(shaderA.ID, "Lights");
glUniformBlockBinding(shaderA.ID, lights_index, 2);OpenGL 4.2起,可以添加一个布局标识符,显式地将 Uniform 块的绑定点储存在着色器中。
layout(std140, binding = 2) uniform Lights { ... };
绑定UBO 到相同的绑定点上:
glBindBufferBase(GL_UNIFORM_BUFFER, 2, UBO);
// or
glBindBufferRange(GL_UNIFORM_BUFFER, 2, UBO, 0, 152);用以下方式更新 Uniform 缓冲对象:
glBindBuffer(GL_UNIFORM_BUFFER, UBO);
int b = true; // GLSL bool 4 byte.
glBufferSubData(GL_UNIFORM_BUFFER, 144, 4, &b);
glBindBuffer(GL_UNIFORM_BUFFER, 0);示例
#version 330 core
layout (location = 0) in vec3 aPos;
layout (std140) uniform Matrices
{
mat4 projection;
mat4 view;
};
uniform mat4 model;
void main()
{
gl_Position = projection * view * model * vec4(aPos, 1.0);
}模型矩阵在不同的着色器中会不断改变,使用Uniform缓冲对象并不方便。
创建UBO,并绑定到绑定点0。
unsigned UBO;
glGenBuffers(1, &UBO);
glBindBuffer(GL_UNIFORM_BUFFER, UBO);
glBufferData(GL_UNIFORM_BUFFER, 2 * sizeof(glm::mat4), NULL, GL_STATIC_DRAW);
glBindBuffer(GL_UNIFORM_BUFFER, 0);
glBindBufferRange(GL_UNIFORM_BUFFER, 0, UBO, 0, 2 * sizeof(glm::mat4));顶点着色器 Uniform 块设置为绑定点0。
unsigned uidx1 = glGetUniformBlockIndex(shader1.ID, "Matrices");
unsigned uidx2 = glGetUniformBlockIndex(shader2.ID, "Matrices");
glUniformBlockBinding(shader1.ID, uidx1, 0);
glUniformBlockBinding(shader2.ID, uidx2, 0);使用 glBufferSubData 在进入rendering loop 前存储投影矩阵。
glm::mat4 projection = glm::perspective(glm::radians(45.0f), width/height, 0.1f, 100.0f);
glBindBuffer(GL_UNIFORM_BUFFER, UBO);
glBufferSubData(GL_UNIFORM_BUFFER, 0, sizeof(glm::mat4), glm::value_ptr(projection));
glBindBuffer(GL_UNIFORM_BUFFER, 0);每次渲染迭代中绘制物体之前,将观察矩阵更新到缓冲的后半部分。
glm::mat4 view = camera.GetViewMat();
glBindBuffer(GL_UNIFORM_BUFFER, UBO);
glBufferSubData(GL_UNIFORM_BUFFER, sizeof(glm::mat4), sizeof(glm::mat4), glm::value_ptr(view));
glBindBuffer(GL_UNIFORM_BUFFER, 0);UBO 的优势
- 一次设置多个 uniform 会比一个个设置 uniform 快。
- 在 Uniform 缓冲中修改一次 uniform 比在多个着色器中修改同样的 uniform 更容易。
- OpenGL 限制了最多能处理的 uniform 数量,通过 GL_MAX_VERTEX_UNIFORM_COMPONENTS 查询,使用 UBO 数量会更多。
Geometry Shader
几何着色器(Geometry Shader) 在顶点和片段着色器之间,输入是一个图元的一组顶点,它能够将顶点变换为完全不同的图元,还能生成比原来更多的顶点。
几何着色器顶部,声明从顶点着色器输入的图元类型。
layout (points) in;
points:绘制 GL_POINTS。(1)- ‘
lines:绘制 GL_LINES 或 GL_LINE_STRIP。(2)lines_adjacency:GL_LINES_ADJACENCY 或 GL_LINE_STRIP_ADJACENCY。(4)triangles:GL_TRIANGLES、GL_TRIANGLE_STRIP 或 GL_TRIANGLE_FAN。(3)triangles_adjacency:GL_TRIANGLES_ADJACENCY、GL_TRIANGLES_ADJACENCY 或GL_TRIANGLE_STRIP_ADJACENCY。(6)()里面的数字是一个图元包含的最少顶点数。
声明几何着色器输出的图元类型,并设置最多输出的顶点数量。
pointsline_striptriangle_strip
GLSL 提供内建变量(几何着色器输入是一个图元所有顶点,一般多于 1 个,因此被声明为一个数组)。
in gl_Vertex
{
vec4 gl_Position;
float gl_PointSize;
float gl_ClipDistance[];
} gl_in[];几何着色器的使用
准备四个点(不需要 z 方向坐标):
const float points[] =
{
// position color
-0.5f, 0.5f, 1.0f, 0.0f, 0.0f,
0.5f, 0.5f, 0.0f, 1.0f, 0.0f,
0.5f, -0.5f, 0.0f, 0.0f, 1.0f,
-0.5f, -0.5f, 1.0f, 1.0f, 0.0f
};顶点着色器
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;
out VS_OUT {
vec3 v_color;
} vs_out;
void main()
{
gl_Position = vec4(aPos.x, aPos.y, 0.0, 1.0);
vs_out.v_color = aColor;
}在几何着色器上绘制图案(几何着色器编译链接与其他着色器一样):
#version 330 core
layout (points) in;
layout (triangle_strip, max_vertices = 5) out;
in VS_OUT {
vec3 v_color;
} gs_in[];
out vec3 g_color;
const float scale = 0.25;
void main()
{
g_color = gs_in[0].v_color;
gl_Position = gl_in[0].gl_Position + vec4(-scale, -scale, 0.0, 0.0);
g_color = vec3(1.0);
EmitVertex();
gl_Position = gl_in[0].gl_Position + vec4( scale, -scale, 0.0, 0.0);
g_color = vec3(1.0);
EmitVertex();
gl_Position = gl_in[0].gl_Position + vec4(-scale, scale, 0.0, 0.0);
g_color = gs_in[0].v_color;
EmitVertex();
gl_Position = gl_in[0].gl_Position + vec4( scale, scale, 0.0, 0.0);
EmitVertex();
g_color = gs_in[0].v_color;
gl_Position = gl_in[0].gl_Position + vec4( 0.0, 2 * scale, 0.0, 0.0);
// top point color
g_color = vec3(1.0);
EmitVertex();
EndPrimitive();
}调用
EmitVertex时,gl_Position 向量会被添加到图元中。调用EndPrimitive时,发射出的(Emitted)顶点会合成为指定输出渲染图元。EmitVertex调用之后重复调用EndPrimitive能够生成多个图元。
片段着色器
#version 330 core
out vec4 FragColor;
in vec3 g_color;
void main()
{
FragColor = vec4(g_color, 1.0);
}
物体爆炸
把每个三角形沿着法向量的方向移动一小段距离。
使用 3 个输入顶点坐标来获取法向量,使用叉乘来获取垂直于其它两个向量的一个向量:
vec3 get_normal()
{
vec3 a = vec3(gl_in[0].gl_Position) - vec3(gl_in[1].gl_Position);
vec3 b = vec3(gl_in[2].gl_Position) - vec3(gl_in[1].gl_Position);
return normalize(cross(a, b));
}用法向量和顶点位置向量作为参数,会返回一个新的向量,即位置向量沿着法线向量进行位移之后的结果。
vec4 explode(vec4 position, vec3 normal)
{
float magnitude = 2.0;
vec3 direction = normal * ((sin(time) + 1.0) / 2.0) * magnitude;
return position + vec4(direction, 0.0);
}完整的物体爆炸几何着色器
#version 330 core
layout (triangles) in;
layout (triangle_strip, max_vertices = 3) out;
in VS_OUT {
vec2 texCoords;
} gs_in[];
out vec2 TexCoords;
// shader.setFloat("time", glfwGetTime());
uniform float time;
vec3 get_normal()
{
vec3 a = vec3(gl_in[0].gl_Position) - vec3(gl_in[1].gl_Position);
vec3 b = vec3(gl_in[2].gl_Position) - vec3(gl_in[1].gl_Position);
return normalize(cross(a, b));
}
vec4 explode(vec4 position, vec3 normal)
{
float magnitude = 2.0;
vec3 direction = normal * ((sin(time) + 1.0) / 2.0) * magnitude;
return position + vec4(direction, 0.0);
}
void main() {
vec3 normal = get_normal();
gl_Position = explode(gl_in[0].gl_Position, normal);
TexCoords = gs_in[0].texCoords;
EmitVertex();
gl_Position = explode(gl_in[1].gl_Position, normal);
TexCoords = gs_in[1].texCoords;
EmitVertex();
gl_Position = explode(gl_in[2].gl_Position, normal);
TexCoords = gs_in[2].texCoords;
EmitVertex();
EndPrimitive();
}法向量可视化
使用模型提供的顶点法线
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aNormal;
out VS_OUT {
vec3 normal;
} vs_out;
uniform mat4 projection;
uniform mat4 view;
uniform mat4 model;
void main()
{
gl_Position = projection * view * model * vec4(aPos, 1.0);
mat3 normalMatrix = mat3(transpose(inverse(view * model)));
vs_out.normal = normalize(vec3(projection * vec4(normalMatrix * aNormal, 0.0)));
}几何着色器会接收每一个顶点(包括一个位置向量和一个法向量),并在每个位置向量处绘制一个法线向量:
#version 330 core
layout (triangles) in;
layout (line_strip, max_vertices = 6) out;
in VS_OUT {
vec3 normal;
} gs_in[];
const float MAGNITUDE = 0.4;
void draw_line(int index)
{
gl_Position = gl_in[index].gl_Position;
EmitVertex();
gl_Position = gl_in[index].gl_Position + vec4(gs_in[index].normal, 0.0) * MAGNITUDE;
EmitVertex();
EndPrimitive();
}
void main()
{
draw_line(0);
draw_line(1);
draw_line(2);
}使用片段着色器,将其显示为单色的线。
#version 330 core
out vec4 FragColor;
void main()
{
FragColor = vec4(1.0, 0.0, 0.0, 1.0);
}该几何着色器也经常用于给物体添加毛发。
Instancing
将数据一次性发送给 GPU,使用一个绘制函数让 OpenGL 利用这些数据绘制多个物体,即实例化(Instancing)。
glDrawArrays:glDrawArraysInstancedglDrawElements:glDrawElementsInstanced
渲染函数实例化版本需要一个额外的参数,实例数量来设置需要渲染的实例个数。GPU 会直接渲染实例,而不用频繁地与 CPU 进行通信。
GLSL 在顶点着色器中嵌入了一个内建变量 gl_InstanceID,从0开始,在每个实例被渲染时递增 1。
实例化数组
定义为一个顶点属性,仅在顶点着色器渲染一个新的实例时才会更新。
实例位置:
glm::vec2 translations[100];
int index = 0;
float offset = 0.1f;
for(int y = -10; y < 10; y += 2)
{
for(int x = -10; x < 10; x += 2)
{
glm::vec2 translation;
translation.x = (float)x / 10.0f + offset;
translation.y = (float)y / 10.0f + offset;
translations[index++] = translation;
}
}实例缓冲:
glBindVertexArray(quadVAO);
unsigned instanceVBO;
glGenBuffers(1, &instanceVBO);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(glm::vec2) * 100, &translations, GL_STATIC_DRAW);
glEnableVertexAttribArray(2);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)0);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glVertexAttribDivisor(2, 1);
glVertexAttribDivisor告诉 OpenGL 什么情况下更新顶点属性的内容至新一组数据。
- param1:顶点属性。
- param2:属性除数。默认 0,在顶点着色器的每次迭代时更新顶点属性;设置为 n,染 n 个新实例的时候更新顶点属性。
顶点着色器:
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;
layout (location = 2) in vec2 aOffset;
out vec3 v_color;
void main()
{
gl_Position = vec4(aPos * gl_InstanceID / 100.0 + aOffset, 0.0, 1.0);
v_color = aColor;
}片段着色器:
#version 330 core
out vec4 FragColor;
in vec3 v_color;
void main()
{
FragColor = vec4(v_color, 1.0);
}绘制方式:
shader.active();
glBindVertexArray(quadVAO);
glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100);
glBindVertexArray(0);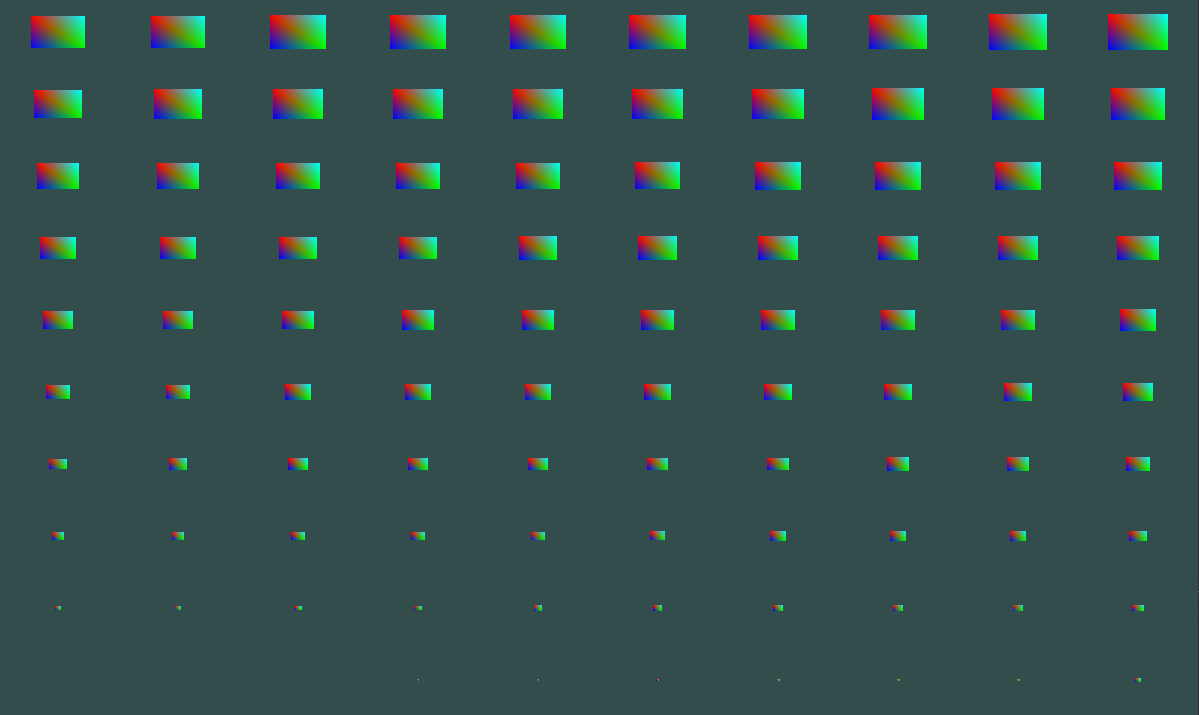
Anti Aliasing
抗锯齿(Anti-aliasing)是为了产生更平滑的边缘。
多重采样(Multisampling)
光栅器将一个图元所有顶点作为输入,并将它转换为一系列的片段。顶点坐标与片段之间基本不会有一对一映射,因此光栅器需要以某种方式来决定每个顶点最终所在的片段(屏幕坐标)。
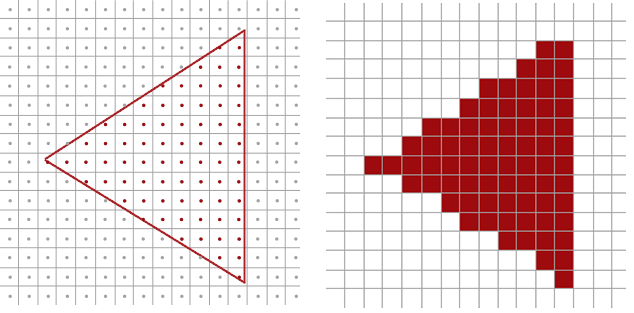
多重采样是将单一采样点变为多个采样点,不使用像素中心的单一采样点,而是以特定图案排列的 4 个子采样点。用这些子采样点来决定像素的覆盖度,颜色缓冲的大小会随着子采样点的增加而增加。
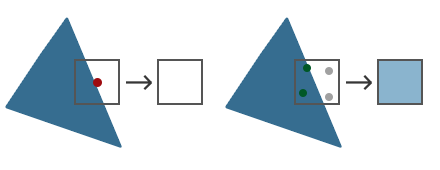
采样点的数量可以是任意的,更多的采样点能带来更精确的覆盖率。
MSAA(Multisample Anti-aliasing)工作方式:不管三角形覆盖了多少子采样点,每个图元中每个像素只运行一次片段着色器,片段着色器使用的顶点数据会插值到每个像素的中心,结果颜色被储存在每个被覆盖的子采样点中。
当颜色缓冲的子样本被图元的所有颜色填满时,所有的颜色会在每个像素内部平均化。
MSAA in OpenGL
在 OpenGL 中使用 MSAA,要使用一个能在每个像素中存储大于 1 个颜色值的颜色缓冲(多重采样为每个采样点储存一个颜色)。存储特定数量的多重采样样本的多重采样缓冲(Multisample Buffer)。
在创建窗口之前调用 glfwWindowHint 来完成。
glfwWindowHint(GLFW_SAMPLES, 4);调用glfwCreateWindow创建渲染窗口时,每个屏幕坐标就会使用一个包含 4 个子采样点的颜色缓冲。
GLFW 会自动创建一个每像素 4 个子采样点的深度和样本缓冲,因此对应缓冲的大小都变为 4 倍。
启用多重采样。
glEnable(GL_MULTISAMPLE);离屏 MSAA
用自己的帧缓冲进行离屏渲染,要动手生成多重采样缓冲。
创建支持储存多个采样点的纹理,使用 glTexImage2DMultisample,纹理目标 GL_TEXTURE_2D_MULTISAPLE。
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, texture);
// samples是采样个数,最后一个参数为GL_TRUE,图像对每个纹素使用相同的样本位置、相同数量的子采样点个数。
glTexImage2DMultisample(GL_TEXTURE_2D_MULTISAMPLE, samples, GL_RGB, width, height, GL_TRUE);
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, 0);使用 glFramebufferTexture2D 将多重采样纹理附加到帧缓冲上,纹理类型 GL_TEXTURE_2D_MULTISAMPLE。
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0,
GL_TEXTURE_2D_MULTISAMPLE, texture, 0);当前绑定的帧缓冲就有了一个纹理图像形式的多重采样颜色缓冲。
多重采样渲染缓冲对象:在指定(当前绑定的)渲染缓冲的内存存储时,将 glRenderbufferStorage 改为glRenderbufferStorageMultisample。
glRenderbufferStorageMultisample(GL_RENDERBUFFER, 4, GL_DEPTH24_STENCIL8, width, height);渲染到多重采样帧缓冲:
glBindFramebuffer(GL_READ_FRAMEBUFFER, multisampledFBO);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0);
glBlitFramebuffer(0, 0, width, height, 0, 0, width, height, GL_COLOR_BUFFER_BIT, GL_NEAREST);自定义抗锯齿算法
将纹理 uniform 采样器设置为 sampler2DMS
uniform sampler2DMS screenTextureMS;使用 texelFetch 获取每个子样本的颜色值:
vec4 colorSample = texelFetch(screenTextureMS, TexCoords, i); // 第i+1子样本 

- 本文链接:https://morisa66.github.io/2021/01/21/OpenGL2/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。