CPP内存管理
简介
堆(heap)
是动态分配内存的区域,跟数据结构里的堆不是一回事,内存被分配之后需要手工释放,否则会造成内存泄漏。
C++ 标准里一个相关概念是自由存储区,英文是 free store,特指使用 new 和 delete 来分配和释放内存的区域。
一般而言,这是堆的一个子集。
- new 和 delete 操作的区域是 free store。
- malloc 和 free 操作的区域是 heap。
new 和 delete 通常底层使用 malloc 和 free 来实现,所以 free store 也是 heap,对其区分的实际意义并不大。
栈(stack)
是函数调用过程中产生的本地变量和调用数据的区域。
和数据结构里的栈高度相似,都满足后进先出(last-in-first-out 或 LIFO)。
资源获取即初始化 RAII(Resource Acquisition Is Initialization)
依托栈和析构函数,来对所有的资源(包括堆内存在内)进行管理。
RAII是一种惯用法,把资源的有效期跟持有资源的对象的生命周期绑定到一起。它靠构造函数来完成资源的分配,并利用析构函数来完成资源的释放。
RAII跟析构函数关系非常紧密,但概念上并不等同。
C++对象在销毁的时候会自动调用析构函数,所谓RAII机制其实就是在对象构造的时候初始化它所需要的资源,在析构的时候自动释放它持有的资源。
堆内存分配
使用堆,或者说使用动态内存分配,是一件很自然的事情。
// C++
auto ptr = new std::vector<int>();在堆上分配内存,有些语言可能使用 new 这样的关键字,有些语言则是在对象的构造时隐式分配,不需要特殊关键字。不管哪种情况,程序通常需要牵涉到三个可能的内存管理器的操作:
- 让内存管理器分配一个某个大小的内存块。
- 让内存管理器释放一个之前分配的内存块。
- 让内存管理器进行垃圾收集操作,寻找不再使用的内存块并予以释放。
CPP:1、2, JAVA:1、3, PYTHON:1、2、3
分配内存要考虑程序当前已经有多少未分配的内存。内存不足时要从操作系统申请新的内存。内存充足时,要从可用的内存里取出一块合适大小的内存,做簿记工作将其标记为已用,然后将其返回给要求内存的代码。
需要注意到,绝大部分情况下,可用内存都会比要求分配的内存大,所以代码只被允许使用其被分配的内存区域,而剩余的内存区域仍属于未分配状态,可以在后面的分配过程中使用。另外,如果内存管理器支持垃圾收集的话,分配内存的操作还可能会触发垃圾收集。
释放内存不只是简单地把内存标记为未使用。对于连续未使用的内存块,通常内存管理器需要将其合并成一块,以便可以满足后续的较大内存分配要求。毕竟,目前的编程模式都要求申请的内存块是连续的。
垃圾收集操作有很多不同的策略和实现方式,以实现性能、实时性、额外开销等各方面的平衡。由于 C++ 里通常都不使用垃圾收集,不再说明。
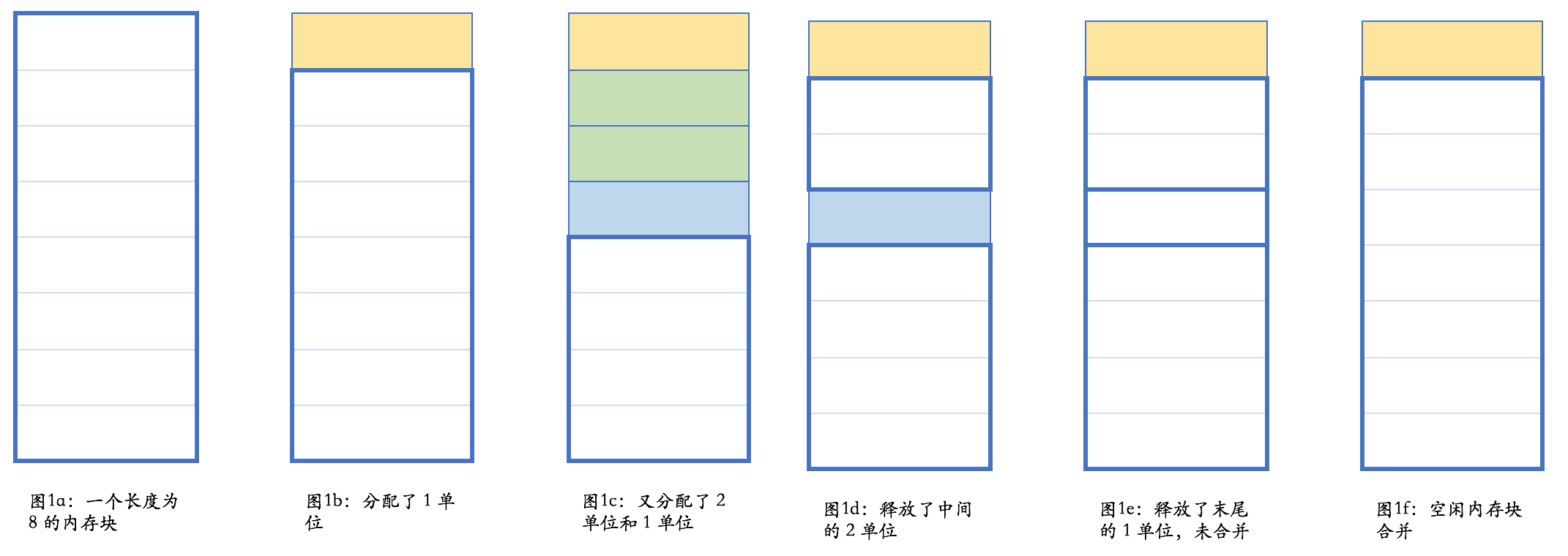
在图 1e 的状态下,内存管理器是满足不了长度大于 4 的内存分配要求的;而在图 1f 的状态,则长度小于等于 7 的单个内存要求都可以得到满足。在不考虑垃圾收集的情况下,内存需要手工释放;在此过程中,内存可能有碎片化的情况。比如,在图 1d 的情况下,虽然总共剩余内存为 6,但却满足不了长度大于 4 的内存分配要求。
内存分配和释放的管理,是内存管理器的任务,一般情况下我们不需要介入。我们只需要正确地使用 new 和 delete。每个 new 出来的对象都应该用 delete 来释放,就是这么简单。
事实说明,漏掉 delete 是一种常见的情况,这叫内存泄漏。
void foo() { bar* ptr = new bar(); // xxxxxx delete ptr; }上面的代码存在问题:
- xxxxxx可能抛异常导致
delete ptr不执行。- 不符合 C++ 的惯用法,不应该使用堆内存分配,而应使用栈内存分配。
bar* make_bar(...) { bar* ptr = nullptr; try { ptr = new bar(); // xxxxxx } catch (...) { delete ptr; throw; } return ptr; } void foo() { // xxxxxx bar* ptr = make_bar(...) // xxxxxx delete ptr; }上面的代码存在问题:分配和释放不在一个函数里。
栈内存分配
栈内存分配更符合 C++ 特性
void foo(int n)
{
// xxxxxx
}
void bar(int n)
{
int a = n + 1;
foo(a);
}
int main()
{
// xxxxxx
bar(42);
// xxxxxx
}上面代码执行过程中的栈变化
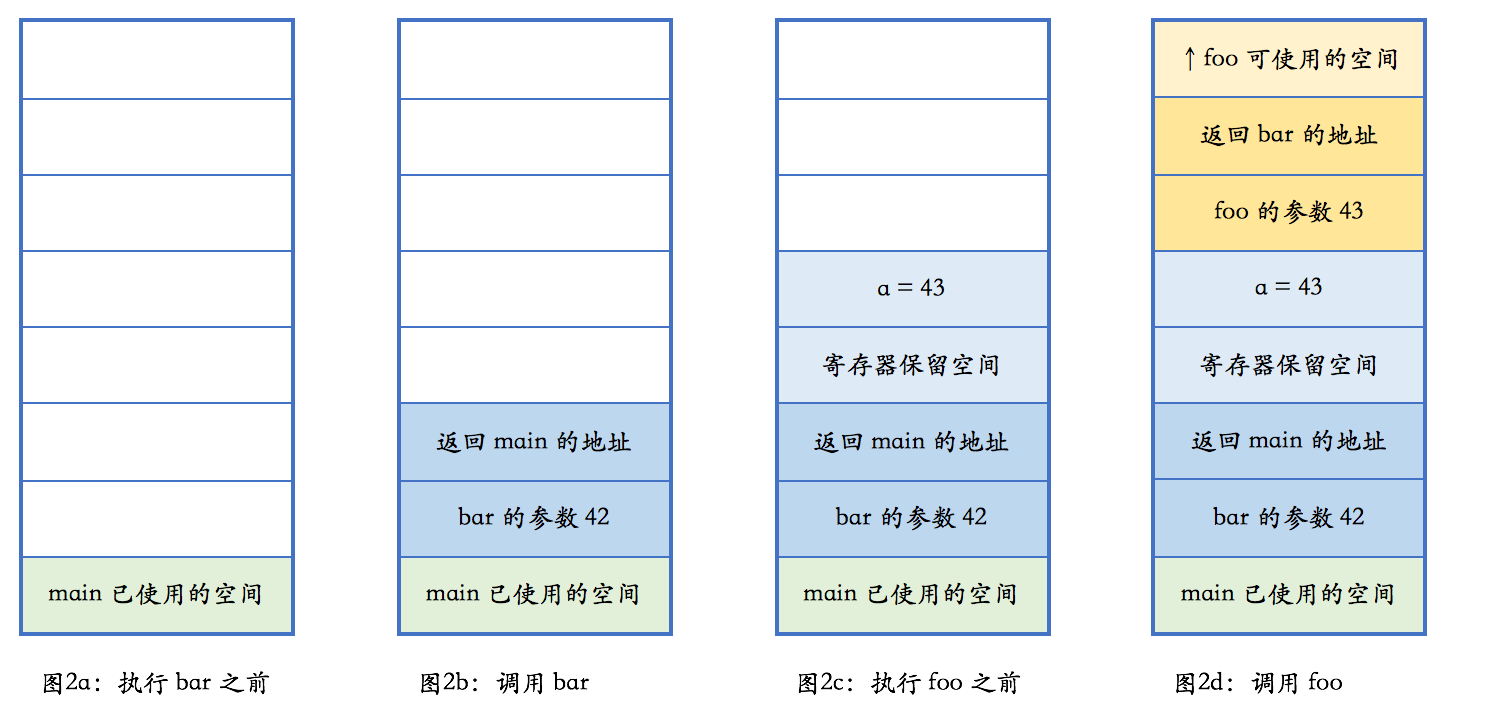
栈是向上增长的。在包括 x86 在内的大部分计算机体系架构中,栈的增长方向是低地址,因而上方意味着低地址。任何一个函数,根据架构的约定,只能使用进入函数时栈指针向上部分的栈空间。当函数调用另外一个函数时,会把参数也压入栈里(我们此处忽略使用寄存器传递参数的情况),然后把下一行汇编指令的地址压入栈,并跳转到新的函数。新的函数进入后,首先做一些必须的保存工作,然后会调整栈指针,分配出本地变量所需的空间,随后执行函数中的代码,并在执行完毕之后,根据调用者压入栈的地址,返回到调用者未执行的代码中继续执行。
每种颜色都表示某个函数占用的栈空间。这部分空间有个特定的术语,叫做栈帧(stack frame)。GCC 和 Clang 的命令行参数中提到 frame 的,如 -fomit-frame-pointer,一般就是指栈帧。
本地变量所需内存在栈上,跟函数执行所需的其他数据在一起。当函数执行完成后,这些内存就自然然释放掉了。
- 栈上的分配极为简单,移动一下栈指针而已。
- 栈上的释放也极为简单,函数执行结束时移动一下栈指针即可。
- 由于后进先出的执行过程,不可能出现内存碎片。
前面例子的本地变量是简单类型,C++ 里称之为 POD 类型(Plain Old Data)。对于有构造和析构函数的非 POD 类型,栈上的内存分配也同样有效,只不过 C++ 编译器会在生成代码的合适位置,插入对构造和析构函数的调用。
编译器会自动调用析构函数,包括在函数执行发生异常的情况。在发生异常时对析构函数的调用,还有一个专门的术语,叫栈展开(stack unwinding)。
class Obj {
public:
Obj() { puts("Obj()"); }
~Obj() { puts("~Obj()"); }
};
void foo(int n)
{
Obj obj;
if (n == 2)
throw "stack unwinding";
}
int main()
{
try {
foo(1);
foo(2);
}
catch (const char* s) {
puts(s);
}
}
/*
output:
Obj()
~Obj()
Obj()
~Obj()
stack unwinding
*/RAII
C++ 支持将对象存储在栈上面。但是,在很多情况下,对象不能,或不应该,存储在栈上。比如:
- 对象很大。
- 对象的大小在编译时不能确定。
- 对象是函数的返回值,由于特殊的原因,不应使用对象的值返回。
enum class shape_type {
circle,
triangle,
rectangle,
...
};
class shape { ... };
class circle : public shape { ... };
class triangle : public shape { ... };
class rectangle : public shape { ... };
shape* create_shape(shape_type type)
{
...
switch (type) {
case shape_type::circle:
return new circle(...);
case shape_type::triangle:
return new triangle(...);
case shape_type::rectangle:
return new rectangle(...);
...
}
}create_shape 方法会返回一个 shape 对象,对象的实际类型是某个 shape 的子类,这种情况下,函数的返回值只能是指针或其变体形式。如果返回类型是 shape,实际却返回一个 circle,编译器不会报错,但结果多半是错的。这种现象叫对象切片(object slicing),是 C++ 特有的一种编码错误。这种错误不是语法错误,而是一个对象复制相关的语义错误。
怎样确保,在使用 create_shape 的返回值时不会发生内存泄漏?
把这个返回值放到一个本地变量里,并确保其析构函数会删除该对象即可。
class shape_wrapper {
public:
explicit shape_wrapper(shape* ptr = nullptr): ptr_(ptr) {}
~shape_wrapper()
{
delete ptr_;
}
shape* get() const { return ptr_; }
private:
shape* ptr_;
};
void foo()
{
...
shape_wrapper ptr_wrapper(create_shape(...));
...
}delete 空指针是一个合法的空操作,在 new 一个对象和 delete 一个指针时编译器需要干不少活的。
new 的时候先分配内存(失败时整个操作失败并向外抛出异常,通常是 bad_alloc),然后在这个结果指针上构造对象(注意上面示意中的调用构造函数并不是合法的 C++ 代码);构造成功则 new 操作整体完成,否则释放刚分配的内存并继续向外抛构造函数产生的异常。delete 时则判断指针是否为空,在指针不为空时调用析构函数并释放之前分配的内存。
// new circle(...) { void* temp = operator new(sizeof(circle)); try { circle* ptr = static_cast<circle*>(temp); ptr->circle(...); return ptr; } catch (...) { operator delete(ptr); throw; } } if (ptr != nullptr) { ptr->~shape(); operator delete(ptr); }C++中的
explicit关键字只能用于修饰只有一个参数的类构造函数,它的作用是表明该构造函数是显示的,而非隐式的, 跟它相对应的另一个关键字是implicit,意思是隐藏的,类构造函数默认情况下即声明为implicit(隐式)。class CxString // 使用关键字explicit的类声明, 显示转换 { public: char *_pstr; int _size; explicit CxString(int size) { _size = size; _pstr = malloc(size + 1); // 分配string的内存 memset(_pstr, 0, size + 1); } CxString(const char *p) { int size = strlen(p); _pstr = malloc(size + 1); // 分配string的内存 strcpy(_pstr, p); // 复制字符串 _size = strlen(_pstr); } // 析构函数这里不讨论, 省略... }; // 下面是调用: CxString string1(24); // 这样是OK的 CxString string2 = 10; // 这样是不行的, 因为explicit关键字取消了隐式转换 CxString string3; // 这样是不行的, 因为没有默认构造函数 CxString string4("aaaa"); // 这样是OK的 CxString string5 = "bbb"; // 这样也是OK的, 调用的是CxString(const char *p) CxString string6 = 'c'; // 这样是不行的, 其实调用的是CxString(int size), 且size等于'c'的ascii码, 但explicit关键字取消了隐式转换 string1 = 2; // 这样也是不行的, 因为取消了隐式转换 string2 = 3; // 这样也是不行的, 因为取消了隐式转换 string3 = string1; // 这样也是不行的, 因为取消了隐式转换, 除非类实现操作符"="的重载
常见问题
1、全局静态和局部静态的变量是存储在静态存储区,既不是堆也不是栈,它们是在程序编译、链接时完全确定下来,具有固定的存储位置(暂不考虑某些系统的地址扰乱机制)。堆和栈上的变量则都是动态的,地址无法确定。
2、thread_local和静态存储区类似,只不过不是整个程序统一一块,而是每个线程单独一块。用法上还是当成全局/静态变量来用,但不共享也就不需要同步了。
3、类的大小确定方法:非静态数据成员加上动态类型所需的空间,再根据是否虚类看是否加上一个一般是指针的大小(64位系统上是8字节)。要考虑字节对齐的影响。静态数据成员和成员函数都不占个别对象的空间。
4、所有的指针、引用变量(以 &、* 结尾的)都算引用语义,其他的就是值语义了。


- 本文链接:https://morisa66.github.io/2021/03/01/MemoryManagement/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。